
「ヘイSiri、クレジットカードを登録して。番号は……」
音声入力が精度を上げ、日常に浸透していく一方で、周囲へのセキュリティの問題が大きな課題とされています。
2021年2月、アメリカとインドの研究グループ※が、声を出さず口パク状態の顎(あご)の動きから音声認識をするデバイス「JawSense(ジョーセンス)」を発表しました(Jawは顎の意味)。
この記事では、未来の音声コミュニケーションの一部で使われるかもしれない、この音声ウェアラブルデバイスを紹介します。
※ 米ニューヨーク州立大学ストーニーブルック校、インド工科大学ガンディーナガル校、米カリフォルニア・マーセッド大学、米テキサス大学アーリントン校による共同研究グループ
無発声の音声認識の仕組み
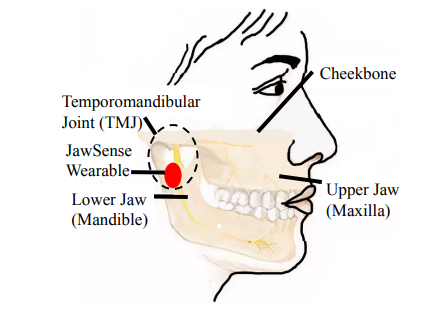
JawSenseのイメージ図
出典:ITmedia
JawSenseのプロトタイプでは、耳に近い部分、顎の関節付近に加速度センサーつきの装置をとりつけ、顎や頬の振動や筋肉の動きから音声なしの音素(言葉を構成する最小の音)を認識します。
神経学や解剖学的な研究を交えて開発が進められており、うなずき、頭の動き、あくびなどの動きや外部環境音のノイズは除去され、声を出しているか口パクなのかは周波数スペクトルを解析して区別されます。
このデバイスは、ヘッドフォンやイヤフォンへの後付けもできるため、手元が塞がる心配もありません。
6人の被験者を対象とした実験では、9つの音素に対して、音声なしの音素検出で92%の分類精度を達成したそうです。
通常、私たちは、
- 肺から空気を送る
- 喉(のど)の声帯を震わせる
- 顎や頬、舌や鼻腔を適切に動かす
という一連のプロセスによって声を発しています。
これらのうち、1と2がなく、3の一部である顎や頬の動きだけで声を認識できるとは驚きです。
無発声の音声認識を活用するメリットは?
今回の研究では、コンピューターとの対話を行った結果(human-computer interaction)とされていますが、無発声の音声認識技術は、以下のような場面での活用が期待されています。
- 合成音声やテキスト作成ツールと連携し、発声が困難な人のコミュニケーション手段
- 公共の場での機密情報のやりとり(プライバシーに関することなど)
- 騒音環境下での情報伝達手段
コロナ禍の下、この装置が一般化され、新しい生活様式が長く続くようであれば、居酒屋で大声を出さなくても会話ができたり、口の動きによって会議のメモをとったりと、無発声の音声認識技術が身近なところで活躍するかもしれません。
まとめ
海外ドラマなどで、危険な場所での潜入捜査をしている主人公チームが耳元の無線で会話をするシーンを見るたびに、「丸聞こえなのでは?」と違和感を抱いていたのですが、JawSenseのようなものを使って、口パクを元にやりとりしてたと考えれば納得ができるかもしれませんね。
今後、いっそうコンパクトな装置で、連続した会話の音声認識の実現を目指しているそうです。
なお、JawSenseに類似の研究として、
- 息を吸いながら話す「SilentVoice」(Microsoft Research)
- 口パクと超音波エコー映像で認識する「SottoVoce」(東京大学とソニーコンピュータサイエンス研究所)
- マウスピース型の装置で認識する「TongueBoard」(Google)
- 口腔内で発した言葉を読み取る「AlterEgo」(マサチューセッツ工科大学)
などもあります。
高度な音声認識が当たり前になりつつある今、もし「声を出さない音声認識」が普及したら、使ってみたいシチュエーションは思い浮かびますか?
音声合成技術やAI活用とともに進化する新たなボイステックの一分野として、ぜひ注目してみてください。


